| Conserved Domains and Protein Classification |
|
|
| |
| |
|
Conserved Domain Database (CDD) |
CDD is a protein annotation resource that consists of a collection of well-annotated multiple sequence alignment models for ancient domains and full-length proteins. These are available as position-specific score matrices (PSSMs) for fast identification of conserved domains in protein sequences via RPS-BLAST. CDD content includes NCBI-curated domains, which use 3D-structure information to explicitly define domain boundaries and provide insights into sequence/structure/function relationships, as well as domain models imported from a number of external source databases (Pfam, SMART, COG, PRK, TIGRFAMs).
|
|
| |
|
CD-Search
&
Batch CD-Search |
CD-Search is NCBI's interface to searching the Conserved Domain Database with protein or nucleotide query sequences. It uses RPS-BLAST, a variant of PSI-BLAST, to quickly scan a set of pre-calculated position-specific scoring matrices (PSSMs) with a protein query. The results of CD-Search are presented as an annotation of protein domains on the user query sequence (illustrated example), and can be visualized as domain multiple sequence alignments with embedded user queries. High confidence associations between a query sequence and conserved domains are shown as specific hits. The CD-Search Help provides additional details, including information about running CD-Search locally.
Batch CD-Search serves as both a web application and a script interface for a conserved domain search on multiple protein sequences, accepting up to 4,000 proteins in a single job. It enables you to view a graphical display of the concise or full search result for any individual protein from your input list, or to download the results for the complete set of proteins. The Batch CD-Search Help provides additional details.
|
|
| |
|
SPARCLE:
Protein Classification |
The
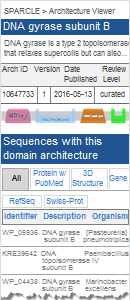
Subfamily Protein Architecture Labeling Engine (SPARCLE) is a resource for the functional characterization and labeling of protein sequences that have been grouped by their characteristic domain architecture. To use SPARCLE, you can either: (1) enter a query protein sequence into CD-Search, which will display a "Protein Classification" on the results page if the query protein has a hit to a curated domain architecture in the SPARCLE database (example, using NP_387887 as the query sequence), or (2) search the SPARCLE database by keyword to retrieve domain architectures that contain the term(s) of interest in their descriptions (example, searching for the words "chloride" and "channel" in the domain architecture record, and limiting the results to curated architectures). With either approach, the corresponding SPARCLE record(s) will display the name and functional label of the architecture, supporting evidence, and links to other proteins with the same architecture.
|
|
| |
|
CDART:
Domain Architectures |
Conserved Domain Architecture Retrieval Tool (CDART) performs similarity searches of the Entrez Protein database based on domain architecture, defined as the sequential order of conserved domains in protein queries. CDART finds protein similarities across significant evolutionary distances using sensitive domain profiles rather than direct sequence similarity. Proteins similar to the query are grouped and scored by architecture. You can search CDART directly with a query protein sequence, or, if a sequence of interest is already in the Entrez Protein database, simply retrieve the record, open its "Links" menu, and select "Domain Relatives" to see the precalculated CDART results (illustrated example). Relying on domain profiles allows CDART to be fast and, because it relies on annotated functional domains, informative.
|
|
| |
|
CDTree |
CDTree is a helper application for your web browser that allows you to interactively view and examine conserved domain hierarchies curated at NCBI. CDTree works with Cn3D as its alignment viewer/editor, it is used in the CDD curation process and is a both classification and research tool for functional annotation and the study of protein and protein domain families. Note that CDTree will no longer be available for download after January 2025
|
|
| |
|
| |
 |
|
|
|
|